Introduction to multi-controller JAX (aka multi-process/multi-host JAX)#
By reading this tutorial, you’ll learn how to scale JAX computations to more devices than can fit in a single host machine, e.g. when running on a GPU cluster, Cloud TPU pod, or multiple CPU-only machines.
The main idea
Run multiple Python processes, which we sometimes call “controllers.” We can run one (or more) process per host machine.
Initialize the cluster with
jax.distributed.initialize().A
jax.Arraycan span all processes, and if each process applies the same JAX function to it, it’s like programming against one big device.Use the same unified sharding mechanism as in single-controller JAX to control how data is distributed and computation is parallelized. XLA automatically exploits high-speed networking links like TPU ICI or NVLink between hosts when available, and otherwise uses available host networking (e.g. Ethernet, InfiniBand).
All processes (usually) run the same Python script. You write this Python code almost exactly the same as you would for a single process — just run multiple instances of it and JAX takes care of the rest. In other words, except for array creation, you can write your JAX code as if there were one giant machine with all devices attached to it.
This tutorial assumes you’ve read Distributed arrays and automatic parallelization, which is about single-controller JAX.

Illustration of a multi-host TPU pod. Each host in the pod (green) is attached via PCI to a board of four TPU chips (blue). The TPUs chips themselves are connected via high-speed inter-chip interconnects (ICI). JAX Python code runs on each host, e.g. via ssh. The JAX processes on each host are aware of each other, allowing you to orchestrate computation across the entire pods’ worth of chips. The principle is the same for GPU, CPU, and other platforms with JAX support!#
Toy example#
Before we define terms and walk through the details, here’s a toy example:
making a process-spanning jax.Array of values and applying
jax.numpy functions to it.
# call this file toy.py, to be run in each process simultaneously
import jax
import jax.numpy as jnp
from jax.sharding import NamedSharding, PartitionSpec as P
import numpy as np
# in this example, get multi-process parameters from sys.argv
import sys
proc_id = int(sys.argv[1])
num_procs = int(sys.argv[2])
# initialize the distributed system
jax.distributed.initialize('localhost:10000', num_procs, proc_id)
# this example assumes 8 devices total
assert jax.device_count() == 8
# make a 2D mesh that refers to devices from all processes
mesh = jax.make_mesh((4, 2), ('i', 'j'))
# create some toy data
global_data = np.arange(32).reshape((4, 8))
# make a process- and device-spanning array from our toy data
sharding = NamedSharding(mesh, P('i', 'j'))
global_array = jax.device_put(global_data, sharding)
assert global_array.shape == global_data.shape
# each process has different shards of the global array
for shard in global_array.addressable_shards:
print(f"device {shard.device} has local data {shard.data}")
# apply a simple computation, automatically partitioned
global_result = jnp.sum(jnp.sin(global_array))
print(f'process={proc_id} got result: {global_result}')
Here, mesh contains devices from all processes. We use it to create
global_array, logically a single shared array, stored distributed across
devices from all processes.
Every process must apply the same operations, in the same order, to
global_array. XLA automatically partitions those computations, for example
inserting communication collectives to compute the jnp.sum over the full
array. We can print the final result because its value is replicated across
processes.
We can run this code locally on CPU, e.g. using 4 processes and 2 CPU devices per process:
export JAX_NUM_CPU_DEVICES=2
num_processes=4
range=$(seq 0 $(($num_processes - 1)))
for i in $range; do
python toy.py $i $num_processes > /tmp/toy_$i.out &
done
wait
for i in $range; do
echo "=================== process $i output ==================="
cat /tmp/toy_$i.out
echo
done
Outputs:
=================== process 0 output ===================
device TFRT_CPU_0 has local data [[0 1 2 3]]
device TFRT_CPU_1 has local data [[4 5 6 7]]
process=0 got result: -0.12398731708526611
=================== process 1 output ===================
device TFRT_CPU_131072 has local data [[ 8 9 10 11]]
device TFRT_CPU_131073 has local data [[12 13 14 15]]
process=1 got result: -0.12398731708526611
=================== process 2 output ===================
device TFRT_CPU_262144 has local data [[16 17 18 19]]
device TFRT_CPU_262145 has local data [[20 21 22 23]]
process=2 got result: -0.12398731708526611
=================== process 3 output ===================
device TFRT_CPU_393216 has local data [[24 25 26 27]]
device TFRT_CPU_393217 has local data [[28 29 30 31]]
process=3 got result: -0.12398731708526611
This might not look so different from single-controller JAX code, and in fact,
this is exactly how you’d write the single-controller version of the same
program! (We don’t technically need to call jax.distributed.initialize()
for single-controller, but it doesn’t hurt.) Let’s run the same code from a
single process:
JAX_NUM_CPU_DEVICES=8 python toy.py 0 1
Outputs:
device TFRT_CPU_0 has local data [[0 1 2 3]]
device TFRT_CPU_1 has local data [[4 5 6 7]]
device TFRT_CPU_2 has local data [[ 8 9 10 11]]
device TFRT_CPU_3 has local data [[12 13 14 15]]
device TFRT_CPU_4 has local data [[16 17 18 19]]
device TFRT_CPU_5 has local data [[20 21 22 23]]
device TFRT_CPU_6 has local data [[24 25 26 27]]
device TFRT_CPU_7 has local data [[28 29 30 31]]
process=0 got result: -0.12398731708526611
The data is sharded across eight devices on one process rather than eight devices across four processes, but otherwise we’re running the same operations over the same data.
Terminology#
It’s worth pinning down some terminology.
We sometimes call each Python process running JAX computations a controller, but the two terms are essentially synonymous.
Each process has a set of local devices, meaning it can transfer data to and
from those devices’ memories and run computation on those devices without
involving any other processes. The local devices are usually physically attached
to the process’s corresponding host, e.g. via PCI. A device can only be local to
one process; that is, the local device sets are disjoint. A process’s local
devices can be queried by evaluating jax.local_devices(). We sometimes
use the term addressable to mean the same thing as local.
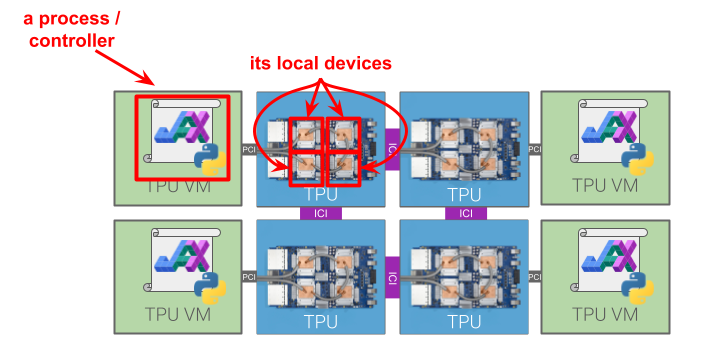
Illustration of how a process/controller and local devices fit into a larger multi-host cluster. The “global devices” are all devices in the cluster.#
The devices across all processes are called the global devices. The list of
global devices is queried by jax.devices(). That list of all devices is
populated by running jax.distributed.initialize() on all processes, which
sets up a simple distributed system connecting the processes.
We often use the terms global and local to describe process-spanning and process-local concepts in general. For example, a “local array” could be a numpy array that’s only visible to a single process, vs. a JAX “global array” is conceptually visible to all processes.
Setting up multiple JAX processes#
In practice, setting up multiple JAX processes looks a bit different from the
toy example, which is run from a single host machine. We usually launch each
process on a separate host, or have multiple hosts with multiple processes each.
We can do that directly using ssh, or with a cluster manager like Slurm or
Kubernetes. In any case, you must manually run your JAX program on each
host! JAX doesn’t automatically start multiple processes from a single program
invocation.
However they’re launched, the Python processes need to run
jax.distributed.initialize(). When using Slurm, Kubernetes, or any Cloud
TPU deployment, we can run jax.distributed.initialize() with no arguments
as they’re automatically populated. Initializing the system means we can run
jax.devices() to report all devices across all processes.
Warning
jax.distributed.initialize() must be called before running
jax.devices(), jax.local_devices(), or running any computations
on devices (e.g. with jax.numpy). Otherwise the JAX process won’t be
aware of any non-local devices. (Using jax.config() or other
non-device-accessing functionality is ok.) jax.distributed.initialize()
will raise an error if you accidentally call it after accessing any devices.
GPU Example#
We can run multi-controller JAX on a cluster of GPU machines.
For example, after creating four VMs on Google Cloud with two GPUs per VM, we
can run the following JAX program on every VM. In this example, we provide
arguments to jax.distributed.initialize() explicitly. The coordinator
address, process id, and number of processes are read from the command line.
# In file gpu_example.py...
import jax
import sys
# Get the coordinator_address, process_id, and num_processes from the command line.
coord_addr = sys.argv[1]
proc_id = int(sys.argv[2])
num_procs = int(sys.argv[3])
# Initialize the GPU machines.
jax.distributed.initialize(coordinator_address=coord_addr,
num_processes=num_procs,
process_id=proc_id)
print("process id =", jax.process_index())
print("global devices =", jax.devices())
print("local devices =", jax.local_devices())
For example, if the first VM has address 192.168.0.1, then you would run
python3 gpu_example.py 192.168.0.1:8000 0 4 on the first VM, python3 gpu_example.py 192.168.0.1:8000 1 4 on the second VM, and so on. After running
the JAX program on all four VMs, the first process prints the following.
process id = 0
global devices = [CudaDevice(id=0), CudaDevice(id=1), CudaDevice(id=2), CudaDevice(id=3), CudaDevice(id=4), CudaDevice(id=5), CudaDevice(id=6), CudaDevice(id=7)]
local devices = [CudaDevice(id=0), CudaDevice(id=1)]
The process successfully sees all eight GPUs as global devices, as well as its two local devices. Similarly, the second process prints the following.
process id = 1
global devices = [CudaDevice(id=0), CudaDevice(id=1), CudaDevice(id=2), CudaDevice(id=3), CudaDevice(id=4), CudaDevice(id=5), CudaDevice(id=6), CudaDevice(id=7)]
local devices = [CudaDevice(id=2), CudaDevice(id=3)]
This VM sees the same global devices, but has a different set of local devices.
TPU Example#
As another example, we can run on Cloud TPU. After creating a
v5litepod-16 (which has 4 host machines), we might want to test that we can
connect the processes and list all devices:
$ TPU_NAME=jax-demo
$ EXTERNAL_IPS=$(gcloud compute tpus tpu-vm describe $TPU_NAME --zone 'us-central1-a' \
| grep externalIp | cut -d: -f2)
$ cat << EOF > demo.py
import jax
jax.distributed.initialize()
if jax.process_index() == 0:
print(jax.devices())
EOF
$ echo $EXTERNAL_IPS | xargs -n 1 -P 0 bash -c '
scp demo.py $0:
ssh $0 "pip -q install -U jax[tpu]"
ssh $0 "python demo.py" '
Here we’re using xargs to run multiple ssh commands in parallel, each one
running the same Python program on one of the TPU host machines. In the Python
code, we use jax.process_index() to print only on one process. Here’s
what it prints:
[TpuDevice(id=0, process_index=0, coords=(0,0,0), core_on_chip=0), TpuDevice(id=1, process_index=0, coords=(1,0,0), core_on_chip=0), TpuDevice(id=4, process_index=0, coords=(0,1,0), core_on_chip=0), TpuDevice(id=5, process_index=0, coords=(1,1,0), core_on_chip=0), TpuDevice(id=2, process_index=1, coords=(2,0,0), core_on_chip=0), TpuDevice(id=3, process_index=1, coords=(3,0,0), core_on_chip=0), TpuDevice(id=6, process_index=1, coords=(2,1,0), core_on_chip=0), TpuDevice(id=7, process_index=1, coords=(3,1,0), core_on_chip=0), TpuDevice(id=8, process_index=2, coords=(0,2,0), core_on_chip=0), TpuDevice(id=9, process_index=2, coords=(1,2,0), core_on_chip=0), TpuDevice(id=12, process_index=2, coords=(0,3,0), core_on_chip=0), TpuDevice(id=13, process_index=2, coords=(1,3,0), core_on_chip=0), TpuDevice(id=10, process_index=3, coords=(2,2,0), core_on_chip=0), TpuDevice(id=11, process_index=3, coords=(3,2,0), core_on_chip=0), TpuDevice(id=14, process_index=3, coords=(2,3,0), core_on_chip=0), TpuDevice(id=15, process_index=3, coords=(3,3,0), core_on_chip=0)]
Woohoo, look at all those TPU cores!
Once the processes are set up, we can start building global jax.Arrays
and running computations. The remaining Python code examples in this tutorial
are meant to be run on all processes simultaneously, after running
jax.distributed.initialize().
Meshes, shardings, and computations can span processes and hosts#
Programming multiple processes from JAX usually looks just like programming a single process, just with more devices! The main exceptions to this are around data coming in or out of JAX, e.g. when loading from external data sources. We’ll first go over the basics of multi-process computations here, which largely look the same as their single-process counterparts. The next section goes over some data loading fundamentals, i.e. how to create JAX Arrays from non-JAX sources.
Recall a jax.sharding.Mesh pairs an array of jax.Devices with
a sequence of names, with one name per array axis. By creating a Mesh using
devices from multiple processes, then using that mesh in a
jax.sharding.Sharding, we can construct jax.Arrays sharded
over devices from multiple processes.
Here’s an example that directly constructs a Mesh using jax.devices()
to get devices from all processes:
from jax.sharding import Mesh
mesh = Mesh(jax.devices(), ('a',))
# in this case, the same as
mesh = jax.make_mesh((jax.device_count(),), ('a',)) # use this in practice
You should probably use the jax.make_mesh() helper in practice, not only
because it’s simpler but also because it can choose more performant device
orderings automatically, but we’re spelling it out here. By default it includes
all devices across processes, just like jax.devices().
Once we have a mesh, we can shard arrays over it. There are a few ways to
efficiently build process-spanning arrays, detailed in the next section, but for
now we’ll stick to jax.device_put for simplicity:
arr = jax.device_put(jnp.ones((32, 32)), NamedSharding(mesh, P('a')))
if jax.process_index() == 0:
jax.debug.visualize_array_sharding(arr)
On process 0, this is printed:
┌───────────────────────┐
│ TPU 0 │
├───────────────────────┤
│ TPU 1 │
├───────────────────────┤
│ TPU 4 │
├───────────────────────┤
│ TPU 5 │
├───────────────────────┤
│ TPU 2 │
├───────────────────────┤
│ TPU 3 │
├───────────────────────┤
│ TPU 6 │
├───────────────────────┤
│ TPU 7 │
├───────────────────────┤
│ TPU 8 │
├───────────────────────┤
│ TPU 9 │
├───────────────────────┤
│ TPU 12 │
├───────────────────────┤
│ TPU 13 │
├───────────────────────┤
│ TPU 10 │
├───────────────────────┤
│ TPU 11 │
├───────────────────────┤
│ TPU 14 │
├───────────────────────┤
│ TPU 15 │
└───────────────────────┘
Let’s try a slightly more interesting computation!
mesh = jax.make_mesh((jax.device_count() // 2, 2), ('a', 'b'))
def device_put(x, spec):
return jax.device_put(x, NamedSharding(mesh, spec))
# construct global arrays by sharding over the global mesh
x = device_put(jnp.ones((4096, 2048)), P('a', 'b'))
y = device_put(jnp.ones((2048, 4096)), P('b', None))
# run a distributed matmul
z = jax.nn.relu(x @ y)
# inspect the sharding of the result
if jax.process_index() == 0:
jax.debug.visualize_array_sharding(z)
print()
print(z.sharding)
On process 0, this is printed:
┌───────────────────────┐
│ TPU 0,1 │
├───────────────────────┤
│ TPU 4,5 │
├───────────────────────┤
│ TPU 8,9 │
├───────────────────────┤
│ TPU 12,13 │
├───────────────────────┤
│ TPU 2,3 │
├───────────────────────┤
│ TPU 6,7 │
├───────────────────────┤
│ TPU 10,11 │
├───────────────────────┤
│ TPU 14,15 │
└───────────────────────┘
NamedSharding(mesh=Mesh('a': 8, 'b': 2), spec=PartitionSpec('a',), memory_kind=device)
Here, just from evaluating x @ y on all processes, XLA is automatically
generating and running a distributed matrix multiplication. The result is
sharded against the mesh like P('a', None), since in this case the matmul
included a psum over the 'b' axis.
Warning
When applying JAX computations to process-spanning arrays, to avoid deadlocks
and hangs, it’s crucial that all processes with participating devices run the
same computation in the same order. That’s because the computation may
involve collective communication barriers. If a device over which an array is
sharded does not join in the collective because its controller didn’t issue the
same computation, the other devices are left waiting. For example, if only the
first three processes evaluated x @ y, while the last process evaluated y @ x, the computation would likely hang indefinitely. This assumption,
computations on process-spanning arrays are run on all participating processes
in the same order, is mostly unchecked.
So the easiest way to avoid deadlocks in multi-process JAX is to run the same
Python code on every process, and beware of any control flow that depends on
jax.process_index() and includes communication.
If a process-spanning array is sharded over devices on different processes, it
is an error to perform operations on the array that require the data to be
available locally to a process, like printing. For example, if we run print(z)
in the preceding example, we see
RuntimeError: Fetching value for `jax.Array` that spans non-addressable (non process local) devices is not possible. You can use `jax.experimental.multihost_utils.process_allgather` to print the global array or use `.addressable_shards` method of jax.Array to inspect the addressable (process local) shards.
To print the full array value, we must first ensure it’s replicated over
processes (but not necessarily over each process’s local devices), e.g. using
jax.device_put. In the above example, we can write at the end:
w = device_put(z, P(None, None))
if jax.process_index() == 0:
print(w)
Be careful not to write the jax.device_put() under the if process_index() == 0, because that would lead to a deadlock as only process 0 initiates the
collective communication and waits indefinitely for the other processes.
The jax.experimental.multihost_utils module has some functions that
make it easier to process global jax.Arrays (e.g.,
jax.experimental.multihost_utils.process_allgather()).
Alternatively, to print or otherwise perform Python operations on only
process-local data, we can access z.addressable_shards. Accessing that
attribute does not require any communication, so any subset of processes can do
it without needing the others. That attribute is not available under a
jax.jit().
Making process-spanning arrays from external data#
There are three main ways to create process-spanning jax.Arrays from
external data sources (e.g. numpy arrays from a data loader):
Create or load the full array on all processes, then shard onto devices using
jax.device_put();Create or load on each process an array representing just the data that will be locally sharded and stored on that process’s devices, then shard onto devices using
jax.make_array_from_process_local_data();Create or load on each process’s devices separate arrays, each representing the data to be stored on that device, then assemble them without any data movement using
jax.make_array_from_single_device_arrays().
The latter two are most often used in practice, since it’s often too expensive to materialize the full global data in every process.
The toy example above uses jax.device_put().
jax.make_array_from_process_local_data() is often used for distributed data
loading. It’s not as general as jax.make_array_from_single_device_arrays(),
because it doesn’t directly specify which slice of the process-local data goes
on each local device. This is convenient when loading data-parallel batches,
because it doesn’t matter exactly which microbatch goes on each device. For
example:
# target (micro)batch size across the whole cluster
batch_size = 1024
# how many examples each process should load per batch
per_process_batch_size = batch_size // jax.process_count()
# how many examples each device will process per batch
per_device_batch_size = batch_size // jax.device_count()
# make a data-parallel mesh and sharding
mesh = jax.make_mesh((jax.device_count(),), ('batch'))
sharding = NamedSharding(mesh, P('batch'))
# our "data loader". each process loads a different set of "examples".
process_batch = np.random.rand(per_process_batch_size, 2048, 42)
# assemble a global array containing the per-process batches from all processes
global_batch = jax.make_array_from_process_local_data(sharding, process_batch)
# sanity check that everything got sharded correctly
assert global_batch.shape[0] == batch_size
assert process_batch.shape[0] == per_process_batch_size
assert global_batch.addressable_shards[0].data.shape[0] == per_device_batch_size
jax.make_array_from_single_device_arrays() is the most general way to
build a process-spanning array. It’s often used after performing
jax.device_put()s to send each device its required data. This is the
lowest-level option, since all data movement is performed manually (via e.g.
jax.device_put()). Here’s an example:
shape = (jax.process_count(), jax.local_device_count())
mesh = jax.make_mesh(shape, ('i', 'j'))
sharding = NamedSharding(mesh, P('i', 'j'))
# manually create per-device data equivalent to np.arange(jax.device_count())
# i.e. each device will get a single scalar value from 0..N
local_arrays = [
jax.device_put(
jnp.array([[jax.process_index() * jax.local_device_count() + i]]),
device)
for i, device in enumerate(jax.local_devices())
]
# assemble a global array from the local_arrays across all processes
global_array = jax.make_array_from_single_device_arrays(
shape=shape,
sharding=sharding,
arrays=local_arrays)
# sanity check
assert (np.all(
jax.experimental.multihost_utils.process_allgather(global_array) ==
np.arange(jax.device_count()).reshape(global_array.shape)))